设计ORM
我们从前几节可以看到,所谓ORM,也是建立在JDBC的基础上,通过ResultSet到JavaBean的映射,实现各种查询。有自动跟踪Entity修改的全自动化ORM如Hibernate和JPA,需要为每个Entity创建代理,也有完全自己映射,连INSERT和UPDATE语句都需要手动编写的MyBatis,但没有任何透明的Proxy。
而查询是涉及到数据库使用最广泛的操作,需要最大的灵活性。各种ORM解决方案各不相同,Hibernate和JPA自己实现了HQL和JPQL查询语法,用以生成最终的SQL,而MyBatis则完全手写,每增加一个查询都需要先编写SQL并增加接口方法。
还有一种Hibernate和JPA支持的Criteria查询,用Hibernate写出来类似:
DetachedCriteria criteria = DetachedCriteria.forClass(User.class);
criteria.add(Restrictions.eq("email", email))
.add(Restrictions.eq("password", password));
List<User> list = (List<User>) hibernateTemplate.findByCriteria(criteria);
上述Criteria查询写法复杂,但和JPA相比,还是小巫见大巫了:
var cb = em.getCriteriaBuilder();
CriteriaQuery<User> q = cb.createQuery(User.class);
Root<User> r = q.from(User.class);
q.where(cb.equal(r.get("email"), cb.parameter(String.class, "e")));
TypedQuery<User> query = em.createQuery(q);
query.setParameter("e", email);
List<User> list = query.getResultList();
此外,是否支持自动读取一对多和多对一关系也是全自动化ORM框架的一个重要功能。
如果我们自己来设计并实现一个ORM,应该吸取这些ORM的哪些特色,然后高效实现呢?
设计ORM接口
任何设计,都必须明确设计目标。这里我们准备实现的ORM并不想要全自动ORM那种自动读取一对多和多对一关系的功能,也不想给Entity加上复杂的状态,因此,对于Entity来说,它就是纯粹的JavaBean,没有任何Proxy。
此外,ORM要兼顾易用性和适用性。易用性是指能覆盖95%的应用场景,但总有一些复杂的SQL,很难用ORM去自动生成,因此,也要给出原生的JDBC接口,能支持5%的特殊需求。
最后,我们希望设计的接口要易于编写,并使用流式API便于阅读。为了配合编译器检查,还应该支持泛型,避免强制转型。
以User类为例,我们设计的查询接口如下:
// 按主键查询: SELECT * FROM users WHERE id = ?
User u = db.get(User.class, 123);
// 条件查询唯一记录: SELECT * FROM users WHERE email = ? AND password = ?
User u = db.from(User.class)
.where("email=? AND password=?", "bob@example.com", "bob123")
.unique();
// 条件查询多条记录: SELECT * FROM users WHERE id < ? ORDER BY email LIMIT ?, ?
List<User> us = db.from(User.class)
.where("id < ?", 1000)
.orderBy("email")
.limit(0, 10)
.list();
// 查询特定列: SELECT id, name FROM users WHERE email = ?
User u = db.select("id", "name")
.from(User.class)
.where("email = ?", "bob@example.com")
.unique();
这样的流式API便于阅读,也非常容易推导出最终生成的SQL。
对于插入、更新和删除操作,就相对比较简单:
// 插入User:
db.insert(user);
// 按主键更新更新User:
db.update(user);
// 按主键删除User:
db.delete(User.class, 123);
对于Entity来说,通常一个表对应一个。手动列出所有Entity是非常麻烦的,一定要传入package自动扫描。
最后,ORM总是需要元数据才能知道如何映射。我们不想编写复杂的XML配置,也没必要自己去定义一套规则,直接使用JPA的注解就行。
实现ORM
我们并不需要从JDBC底层开始编写,并且,还要考虑到事务,最好能直接使用Spring的声明式事务。实际上,我们可以设计一个全局DbTemplate,它注入了Spring的JdbcTemplate,涉及到数据库操作时,全部通过JdbcTemplate完成,自然天生支持Spring的声明式事务,因为这个ORM只是在JdbcTemplate的基础上做了一层封装。
在AppConfig中,我们初始化所有Bean如下:
@Configuration
@ComponentScan
@EnableTransactionManagement
@PropertySource("jdbc.properties")
public class AppConfig {
@Bean
DataSource createDataSource() { ... }
@Bean
JdbcTemplate createJdbcTemplate(@Autowired DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
DbTemplate createDbTemplate(@Autowired JdbcTemplate jdbcTemplate) {
return new DbTemplate(jdbcTemplate, "com.itranswarp.learnjava.entity");
}
@Bean
PlatformTransactionManager createTxManager(@Autowired DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}
以上就是我们所需的所有配置。
编写业务逻辑,例如UserService,写出来像这样:
@Component
@Transactional
public class UserService {
@Autowired
DbTemplate db;
public User getUserById(long id) {
return db.get(User.class, id);
}
public User getUserByEmail(String email) {
return db.from(User.class)
.where("email = ?", email)
.unique();
}
public List<User> getUsers(int pageIndex) {
int pageSize = 100;
return db.from(User.class)
.orderBy("id")
.limit((pageIndex - 1) * pageSize, pageSize)
.list();
}
public User register(String email, String password, String name) {
User user = new User();
user.setEmail(email);
user.setPassword(password);
user.setName(name);
user.setCreatedAt(System.currentTimeMillis());
db.insert(user);
return user;
}
...
}
上述代码给出了ORM的接口,以及如何在业务逻辑中使用ORM。下一步,就是如何实现这个DbTemplate。这里我们只给出框架代码,有兴趣的童鞋可以自己实现核心代码:
public class DbTemplate {
private JdbcTemplate jdbcTemplate;
// 保存Entity Class到Mapper的映射:
private Map<Class<?>, Mapper<?>> classMapping;
public <T> T fetch(Class<T> clazz, Object id) {
Mapper<T> mapper = getMapper(clazz);
List<T> list = (List<T>) jdbcTemplate.query(mapper.selectSQL, new Object[] { id }, mapper.rowMapper);
if (list.isEmpty()) {
return null;
}
return list.get(0);
}
public <T> T get(Class<T> clazz, Object id) {
...
}
public <T> void insert(T bean) {
...
}
public <T> void update(T bean) {
...
}
public <T> void delete(Class<T> clazz, Object id) {
...
}
}
实现链式API的核心代码是第一步从DbTemplate调用select()或from()时实例化一个CriteriaQuery实例,并在后续的链式调用中设置它的字段:
public class DbTemplate {
...
public Select select(String... selectFields) {
return new Select(new Criteria(this), selectFields);
}
public <T> From<T> from(Class<T> entityClass) {
Mapper<T> mapper = getMapper(entityClass);
return new From<>(new Criteria<>(this), mapper);
}
}
然后以此定义Select、From、Where、OrderBy、Limit等。在From中可以设置Class类型、表名等:
public final class From<T> extends CriteriaQuery<T> {
From(Criteria<T> criteria, Mapper<T> mapper) {
super(criteria);
// from可以设置class、tableName:
this.criteria.mapper = mapper;
this.criteria.clazz = mapper.entityClass;
this.criteria.table = mapper.tableName;
}
public Where<T> where(String clause, Object... args) {
return new Where<>(this.criteria, clause, args);
}
}
在Where中可以设置条件参数:
public final class Where<T> extends CriteriaQuery<T> {
Where(Criteria<T> criteria, String clause, Object... params) {
super(criteria);
this.criteria.where = clause;
this.criteria.whereParams = new ArrayList<>();
// add:
for (Object param : params) {
this.criteria.whereParams.add(param);
}
}
}
最后,链式调用的尽头是调用list()返回一组结果,调用unique()返回唯一结果,调用first()返回首个结果。
在IDE中,可以非常方便地实现链式调用:
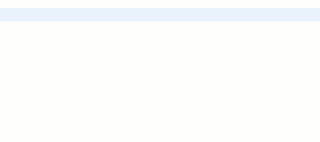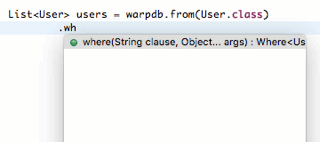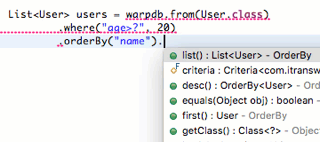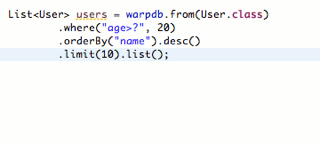
需要复杂查询的时候,总是可以使用JdbcTemplate执行任意复杂的SQL。
练习
设计并实现一个微型ORM。
小结
ORM框架就是自动映射数据库表结构到JavaBean的工具,设计并实现一个简单高效的ORM框架并不困难。