设计撮合引擎
在证券交易系统中,撮合引擎是实现买卖盘成交的关键组件。我们先分析撮合引擎的工作原理,然后设计并实现一个最简化的撮合引擎。
在证券市场中,撮合交易是一种微观价格发现模型,它允许买卖双方各自提交买卖订单并报价,按价格优先,时间优先的顺序,凡买单价格大于等于卖单价格时,双方即达成价格协商并成交。在A股身经百战的老股民对此规则应该非常熟悉,这里不再详述。
我们将讨论如何从技术上来实现它。对于撮合引擎来说,它必须维护两个买卖盘列表,一个买盘,一个卖盘,买盘按价格从高到低排序,确保报价最高的订单排在最前面;卖盘则相反,按照价格从低到高排序,确保报价最低的卖单排在最前面。
下图是一个实际的买卖盘:
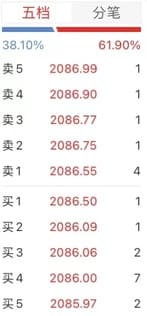
对于买盘来说,上图的订单排序为2086.50,2086.09,2086.06,2086.00,2085.97,……
对于卖盘来说,上图的订单排序为2086.55,2086.75,2086.77,2086.90,2086.99,……
不可能出现买1价格大于等于卖1价格的情况,因为这意味着应该成交的买卖订单没有成交却在订单簿上等待成交。
对于多个价格相同的订单,例如2086.55,很可能张三卖出1,李四卖出3,累计数量是4。当一个新的买单价格≥2086.55时,到底优先和张三的卖单成交还是优先和李四的卖单成交呢?这要看张三和李四的订单时间谁更靠前。
我们在订单上虽然保存了创建时间,但排序时,是根据定序ID即sequenceId来排序,以确保全局唯一。时间本身实际上是订单的一个普通属性,仅展示给用户,不参与业务排序。
下一步是实现订单簿OrderBook的表示。一个直观的想法是使用List<Order>,并对订单进行排序。但是,在证券交易中,使用List会导致两个致命问题:
- 插入新的订单时,必须从头扫描
List<Order>,以便在合适的地方插入Order,平均耗时O(N); - 取消订单时,也必须从头扫描
List<Order>,平均耗时O(N)。
更好的方法是使用红黑树,它是一种自平衡的二叉排序树,插入和删除的效率都是O(logN),对应的Java类是TreeMap。
所以我们定义OrderBook的结构就是一个TreeMap<OrderKey, OrderEntity>,它的排序根据OrderKey决定。由业务规则可知,负责排序的OrderKey只需要sequenceId和price即可:
// 以record实现的OrderKey:
public record OrderKey(long sequenceId, BigDecimal price) {
}
因此,OrderBook的核心数据结构就可以表示如下:
public class OrderBook {
public final Direction direction; // 方向
public final TreeMap<OrderKey, Order> book; // 排序树
public OrderBook(Direction direction) {
this.direction = direction;
this.book = new TreeMap<>(???);
}
}
有的童鞋注意到TreeMap的排序要求实现Comparable接口或者提供一个Comparator。我们之所以没有在OrderKey上实现Comparable接口是因为买卖盘排序的价格规则不同,因此,编写两个Comparator分别用于排序买盘和卖盘:
private static final Comparator<OrderKey> SORT_SELL = new Comparator<>() {
public int compare(OrderKey o1, OrderKey o2) {
// 价格低在前:
int cmp = o1.price().compareTo(o2.price());
// 时间早在前:
return cmp == 0 ? Long.compare(o1.sequenceId(), o2.sequenceId()) : cmp;
}
};
private static final Comparator<OrderKey> SORT_BUY = new Comparator<>() {
public int compare(OrderKey o1, OrderKey o2) {
// 价格高在前:
int cmp = o2.price().compareTo(o1.price());
// 时间早在前:
return cmp == 0 ? Long.compare(o1.sequenceId(), o2.sequenceId()) : cmp;
}
};
这样,OrderBook的TreeMap排序就由Direction指定:
public OrderBook(Direction direction) {
this.direction = direction;
this.book = new TreeMap<>(direction == Direction.BUY ? SORT_BUY : SORT_SELL);
}
这里友情提示Java的BigDecimal比较大小的大坑:比较两个BigDecimal是否值相等,一定要用compareTo(),不要用equals(),因为1.2和1.20因为scale不同导致equals()返回false。
特别注意
在Java中比较两个BigDecimal的值只能使用compareTo(),不能使用equals()!
再给OrderBook添加插入、删除和查找首元素方法:
public OrderEntity getFirst() {
return this.book.isEmpty() ? null : this.book.firstEntry().getValue();
}
public boolean remove(OrderEntity order) {
return this.book.remove(new OrderKey(order.sequenceId, order.price)) != null;
}
public boolean add(OrderEntity order) {
return this.book.put(new OrderKey(order.sequenceId, order.price), order) == null;
}
现在,有了买卖盘,我们就可以编写撮合引擎了。定义MatchEngine核心数据结构如下:
public class MatchEngine {
public final OrderBook buyBook = new OrderBook(Direction.BUY);
public final OrderBook sellBook = new OrderBook(Direction.SELL);
public BigDecimal marketPrice = BigDecimal.ZERO; // 最新市场价
private long sequenceId; // 上次处理的Sequence ID
}
一个完整的撮合引擎包含一个买盘、一个卖盘和一个最新成交价(初始值为0)。撮合引擎的输入是一个OrderEntity实例,每处理一个订单,就输出撮合结果MatchResult,核心处理方法定义如下:
public MatchResult processOrder(long sequenceId, OrderEntity order) {
...
}
下面我们讨论如何处理一个具体的订单。对于撮合交易来说,如果新订单是一个买单,则首先尝试在卖盘中匹配价格合适的卖单,如果匹配成功则成交。一个大的买单可能会匹配多个较小的卖单。当买单被完全匹配后,说明此买单已完全成交,处理结束,否则,如果存在未成交的买单,则将其放入买盘。处理卖单的逻辑是类似的。
我们把已经挂在买卖盘的订单称为挂单(Maker),当前正在处理的订单称为吃单(Taker),一个Taker订单如果未完全成交则转为Maker挂在买卖盘,因此,处理当前Taker订单的逻辑如下:
public MatchResult processOrder(long sequenceId, OrderEntity order) {
switch (order.direction) {
case BUY:
// 买单与sellBook匹配,最后放入buyBook:
return processOrder(order, this.sellBook, this.buyBook);
case SELL:
// 卖单与buyBook匹配,最后放入sellBook:
return processOrder(order, this.buyBook, this.sellBook);
default:
throw new IllegalArgumentException("Invalid direction.");
}
}
MatchResult processOrder(long sequenceId, OrderEntity takerOrder, OrderBook makerBook, OrderBook anotherBook) {
...
}
根据价格匹配,直到成交双方有一方完全成交或成交条件不满足时结束处理,我们直接给出processOrder()的业务逻辑代码:
MatchResult processOrder(long sequenceId, OrderEntity takerOrder, OrderBook makerBook, OrderBook anotherBook) {
this.sequenceId = sequenceId;
long ts = takerOrder.createdAt;
MatchResult matchResult = new MatchResult(takerOrder);
BigDecimal takerUnfilledQuantity = takerOrder.quantity;
for (;;) {
OrderEntity makerOrder = makerBook.getFirst();
if (makerOrder == null) {
// 对手盘不存在:
break;
}
if (takerOrder.direction == Direction.BUY && takerOrder.price.compareTo(makerOrder.price) < 0) {
// 买入订单价格比卖盘第一档价格低:
break;
} else if (takerOrder.direction == Direction.SELL && takerOrder.price.compareTo(makerOrder.price) > 0) {
// 卖出订单价格比买盘第一档价格高:
break;
}
// 以Maker价格成交:
this.marketPrice = makerOrder.price;
// 待成交数量为两者较小值:
BigDecimal matchedQuantity = takerUnfilledQuantity.min(makerOrder.unfilledQuantity);
// 成交记录:
matchResult.add(makerOrder.price, matchedQuantity, makerOrder);
// 更新成交后的订单数量:
takerUnfilledQuantity = takerUnfilledQuantity.subtract(matchedQuantity);
BigDecimal makerUnfilledQuantity = makerOrder.unfilledQuantity.subtract(matchedQuantity);
// 对手盘完全成交后,从订单簿中删除:
if (makerUnfilledQuantity.signum() == 0) {
makerOrder.updateOrder(makerUnfilledQuantity, OrderStatus.FULLY_FILLED, ts);
makerBook.remove(makerOrder);
} else {
// 对手盘部分成交:
makerOrder.updateOrder(makerUnfilledQuantity, OrderStatus.PARTIAL_FILLED, ts);
}
// Taker订单完全成交后,退出循环:
if (takerUnfilledQuantity.signum() == 0) {
takerOrder.updateOrder(takerUnfilledQuantity, OrderStatus.FULLY_FILLED, ts);
break;
}
}
// Taker订单未完全成交时,放入订单簿:
if (takerUnfilledQuantity.signum() > 0) {
takerOrder.updateOrder(takerUnfilledQuantity,
takerUnfilledQuantity.compareTo(takerOrder.quantity) == 0 ? OrderStatus.PENDING
: OrderStatus.PARTIAL_FILLED,
ts);
anotherBook.add(takerOrder);
}
return matchResult;
}
可见,撮合匹配的业务逻辑是相对简单的。撮合结果记录在MatchResult中,它可以用一个Taker订单和一系列撮合匹配记录表示:
public class MatchResult {
public final Order takerOrder;
public final List<MatchDetailRecord> MatchDetails = new ArrayList<>();
// 构造方法略
}
每一笔撮合记录则由成交双方、成交价格与数量表示:
public record MatchDetailRecord(
BigDecimal price,
BigDecimal quantity,
OrderEntity takerOrder,
OrderEntity makerOrder) {
}
撮合引擎返回的MatchResult包含了本次处理的完整结果,下一步需要把MatchResult发送给清算系统,对交易双方进行清算即完成了整个交易的处理。
我们可以编写一个简单的测试来验证撮合引擎工作是否正常。假设如下的订单依次输入到撮合引擎:
// 方向 价格 数量
buy 2082.34 1
sell 2087.6 2
buy 2087.8 1
buy 2085.01 5
sell 2088.02 3
sell 2087.60 6
buy 2081.11 7
buy 2086.0 3
buy 2088.33 1
sell 2086.54 2
sell 2086.55 5
buy 2086.55 3
经过撮合后最终买卖盘及市场价如下:
2088.02 3
2087.60 6
2086.55 4
---------
2086.55
---------
2086.00 3
2085.01 5
2082.34 1
2081.11 7
如果我们仔细观察整个系统的输入和输出,输入实际上是一系列按时间排序后的订单(实际排序按sequenceId),输出是一系列MatchResult,内部状态的变化就是买卖盘以及市场价的变化。如果两个初始状态相同的MatchEngine,输入的订单序列是完全相同的,则我们得到的MatchResult输出序列以及最终的内部状态也是完全相同的。
下面是问题解答。
如何实现多个交易对?
一个撮合引擎只能处理一个交易对,如果要实现多个交易对,则需要构造一个“多撮合实例”的引擎:
class MatchEngineGroup {
Map<Long, MatchEngine> engines = new HashMap<>();
public MatchResult processOrder(long sequenceId, OrderEntity order) {
// 获得订单的交易对ID:
Long symbolId = order.symbolId;
// 查找交易对所对应的引擎实例:
MatchEngine engine = engines.get(symbolId);
if (engine == null) {
// 该交易对的第一个订单:
engine = new MatchEngine();
engines.put(symbolId, engine);
}
// 由该实例处理订单:
return engine.processOrder(sequenceId, order);
}
}
需要给订单增加symbolId属性以标识该订单是哪个交易对。
参考源码
小结
本文讨论并实现了一个可工作的撮合引擎核心。实现撮合引擎的关键在于将业务模型转换为高效的数据结构。只要保证核心数据结构的简单和高效,撮合引擎的业务逻辑编写是非常容易的。